
Analyzer类
class info
第一个部分,Analyzer类实现了Opcodes接口。
public class Analyzer<V extends Value> implements Opcodes {
}
fields
第二个部分,Analyzer类定义的字段有哪些。
| 领域 | ClassFile | ASM | JVM Frame(local variable + operand stack) |
|---|---|---|---|
| 元素 | Code = code[] + exception_table |
MethodNode = InsnList + TryCatchBlockNode |
Interpreter + Frame |
这字段分成三组:
- 第一组,
insnList表示指令集合,insnListSize表示指令集的大小,handlers表示异常处理的机制,这三个字段都是属于“方法”的内容。 - 第二组,
interpreter、frames和泛型V则是用来模拟“local variable和operand stack”的内容。 - 第三组,
inInstructionsToProcess、instructionsToProcess和numInstructionsToProcess三个字段都是“临时的数据容器”,用来记录过程中的内部状态。
粗略地理解:第一组字段,可以理解为“数据输入”,第三组字段,可以理解为“中间状态”,第二组字段,可以理解为“输出结果”。
public class Analyzer<V extends Value> implements Opcodes {
// 第一组,指令和异常处理,是属于“方法”的内容。
private InsnList insnList;
private int insnListSize;
private List<TryCatchBlockNode>[] handlers;
// 第二组,Interpreter和Frame,是属于“local variable和operand stack”的内容。
private final Interpreter<V> interpreter;
private Frame<V>[] frames;
// 第三组,在运行过程中,记录临时状态的变化量
private boolean[] inInstructionsToProcess;
private int[] instructionsToProcess;
private int numInstructionsToProcess;
}
constructors
第三个部分,Analyzer类定义的构造方法有哪些。
public class Analyzer<V extends Value> implements Opcodes {
public Analyzer(Interpreter<V> interpreter) {
this.interpreter = interpreter;
}
}
methods
第四个部分,Analyzer类定义的方法有哪些。
getter方法
public class Analyzer<V extends Value> implements Opcodes {
public Frame<V>[] getFrames() {
return frames;
}
public List<TryCatchBlockNode> getHandlers(int insnIndex) {
return handlers[insnIndex];
}
}
analyze方法
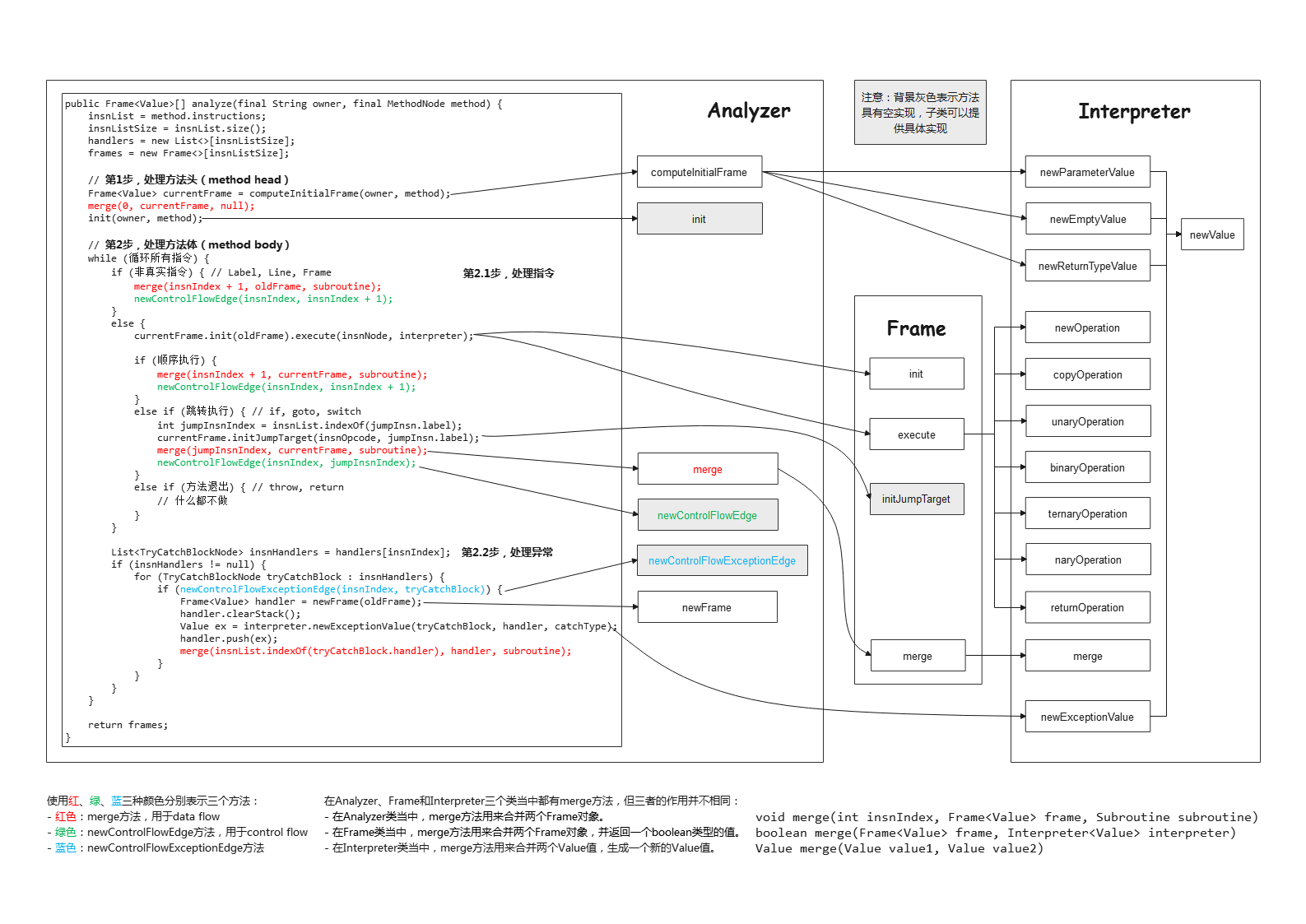
在Analyzer类当中,最重要的方法就是analyze方法。在analyze方法中,会进一步调用其它的方法。
public class Analyzer<V extends Value> implements Opcodes {
public Frame<V>[] analyze(String owner, MethodNode method) throws AnalyzerException {
// 如果方法是abstract或native方法,则直接返回
if ((method.access & (ACC_ABSTRACT | ACC_NATIVE)) != 0) {
frames = (Frame<V>[]) new Frame<?>[0];
return frames;
}
// 为各个字段进行赋值
insnList = method.instructions;
insnListSize = insnList.size();
handlers = (List<TryCatchBlockNode>[]) new List<?>[insnListSize];
frames = (Frame<V>[]) new Frame<?>[insnListSize];
inInstructionsToProcess = new boolean[insnListSize];
instructionsToProcess = new int[insnListSize];
numInstructionsToProcess = 0;
// ...
// 方法头:计算方法的初始Frame
Frame<V> currentFrame = computeInitialFrame(owner, method);
merge(0, currentFrame, null);
init(owner, method);
// 方法体:通过循环对每一条指令进行处理
while (numInstructionsToProcess > 0) {
// 计算每一条指令对应的Frame的状态
// ...
}
return frames;
}
}
computeInitialFrame方法
computeInitialFrame方法根据方法的访问标识(access flag)和方法的描述符(method descriptor)来生成初始的Frame。
public class Analyzer<V extends Value> implements Opcodes {
private Frame<V> computeInitialFrame(final String owner, final MethodNode method) {
// 准备工作:创建一个新的Frame,用来存储下面的数据
Frame<V> frame = newFrame(method.maxLocals, method.maxStack);
int currentLocal = 0;
// 首先,考虑是否需要存储this
boolean isInstanceMethod = (method.access & ACC_STATIC) == 0;
if (isInstanceMethod) {
Type ownerType = Type.getObjectType(owner);
frame.setLocal(currentLocal, interpreter.newParameterValue(isInstanceMethod, currentLocal, ownerType));
currentLocal++;
}
// 接着,存储方法接收的参数
Type[] argumentTypes = Type.getArgumentTypes(method.desc);
for (Type argumentType : argumentTypes) {
frame.setLocal(currentLocal, interpreter.newParameterValue(isInstanceMethod, currentLocal, argumentType));
currentLocal++;
if (argumentType.getSize() == 2) {
frame.setLocal(currentLocal, interpreter.newEmptyValue(currentLocal));
currentLocal++;
}
}
// 再者,如果local variable仍有空间,则设置成empty值。
while (currentLocal < method.maxLocals) {
frame.setLocal(currentLocal, interpreter.newEmptyValue(currentLocal));
currentLocal++;
}
// 最后,设置返回值。
frame.setReturn(interpreter.newReturnTypeValue(Type.getReturnType(method.desc)));
return frame;
}
}
init方法
在Analyzer类当中,init方法是一个空实现,它也是提供了一个机会,一个做“准备工作”的机会。至于做什么样的“准备工作”,需要结合具体的使用场景来决定。
public class Analyzer<V extends Value> implements Opcodes {
/**
* Initializes this analyzer.
* This method is called just before the execution of control flow analysis loop in #analyze.
* The default implementation of this method does nothing.
*/
protected void init(final String owner, final MethodNode method) throws AnalyzerException {
// Nothing to do.
}
}
newFrame方法
newFrame方法的主要作用是创建一个新的Frame对象。
下面的两个newFrame方法就是直接调用Frame类的构造方法,非常直白,那么这两个newFrame方法有什么隐含的用途呢?
public class Analyzer<V extends Value> implements Opcodes {
protected Frame<V> newFrame(int numLocals, int numStack) {
return new Frame<>(numLocals, numStack);
}
protected Frame<V> newFrame(Frame<? extends V> frame) {
return new Frame<>(frame);
}
}
以前的时候,我们介绍过:Analyzer和Frame是属于“固定”的部分,而Interpreter和Value类是属于“变化”的部分。
┌──────────┬─────────────┐
│ │ Analyzer │
│ Fixed ├─────────────┤
│ │ Frame │
├──────────┼─────────────┤
│ │ Interpreter │
│ Variable ├─────────────┤
│ │ Value │
└──────────┴─────────────┘
但是,Analyzer和Frame是相对的“固定”,而不是绝对的“固定”。在有些情况下,ASM提供的Frame类可能不满足实际的应用要求,那么我们就可以修改这两个newFrame方法来替换成我们自己想要使用的Frame的子类。
merge方法
merge方法的主要作用是合并两个Frame对象。
从代码实现上来说,这个merge方法会调用Frame.merge()方法,会再进一步调用Interpreter.merge()方法。
同时,也要注意,我们省略了另一个merge方法,因为该merge方法是处理jsr指令的,而jsr指令已经不推荐使用了。
public class Analyzer<V extends Value> implements Opcodes {
private void merge(final int insnIndex, final Frame<V> frame, final Subroutine subroutine) throws AnalyzerException {
boolean changed;
// 获取旧的Frame对象
Frame<V> oldFrame = frames[insnIndex];
if (oldFrame == null) {
// 如果旧的Frame是null,那么将新的Frame直接存储起来
frames[insnIndex] = newFrame(frame);
changed = true;
} else {
// 如果旧的Frame不是null,那么将旧的Frame和新的Frame进行merge操作
changed = oldFrame.merge(frame, interpreter);
}
// ... 此处省略一段代码,这段代码与jsr指令相关,而jsr指令不推荐使用了。
// 记录下一个需要处理的指令
if (changed && !inInstructionsToProcess[insnIndex]) {
inInstructionsToProcess[insnIndex] = true;
instructionsToProcess[numInstructionsToProcess++] = insnIndex;
}
}
}
ControlFlowEdge方法
下面的newControlFlowEdge和newControlFlowExceptionEdge方法就是实现control flow analysis的关键。
newControlFlowEdge方法:记录正常的跳转:指令的顺序执行、指令的跳转执行(if、switch)。newControlFlowExceptionEdge方法:记录异常的跳转:当程序出现异常的时候,程序应该跳向哪里执行。
public class Analyzer<V extends Value> implements Opcodes {
protected void newControlFlowEdge(int insnIndex, int successorIndex) {
// Nothing to do.
}
protected boolean newControlFlowExceptionEdge(int insnIndex, int successorIndex) {
return true;
}
protected boolean newControlFlowExceptionEdge(int insnIndex, TryCatchBlockNode tryCatchBlock) {
return newControlFlowExceptionEdge(insnIndex, insnList.indexOf(tryCatchBlock.handler));
}
}
实现原理MockAnalyzer
在刚开始接触Analyzer类的时候,不太容易理解。因此,在项目当中,我们提供了MockAnalyzer类,它是对Analyzer类的简化,理解起来更容易一些。借助于MockAnalyzer这个类,我们来讲解一下Analyzer类的实现原理。
class info
第一个部分,MockAnalyzer类实现了Opcodes类。
public class MockAnalyzer<V extends Value> implements Opcodes {
}
fields
第二个部分,MockAnalyzer类定义的字段有哪些。在这个类当中,我们定义了原来的interpreter字段,因为其它的字段都可以转换成局部变量。
public class MockAnalyzer<V extends Value> implements Opcodes {
private final Interpreter<V> interpreter;
}
constructors
第三个部分,MockAnalyzer类定义的构造方法有哪些。
public class MockAnalyzer<V extends Value> implements Opcodes {
public MockAnalyzer(Interpreter<V> interpreter) {
this.interpreter = interpreter;
}
}
methods
第四个部分,MockAnalyzer类定义的方法有哪些。
public class MockAnalyzer<V extends Value> implements Opcodes {
public Frame<V>[] analyze(String owner, MethodNode method) throws AnalyzerException {
// 第一步,如果是abstract或native方法,则直接返回。
if ((method.access & (ACC_ABSTRACT | ACC_NATIVE)) != 0) {
return (Frame<V>[]) new Frame<?>[0];
}
// 第二步,定义局部变量
// (1)数据输入:获取指令集
InsnList insnList = method.instructions;
int size = insnList.size();
// (2)中间状态:记录需要哪一个指令需要处理
boolean[] instructionsToProcess = new boolean[size];
// (3)数据输出:最终的返回结果
Frame<V>[] frames = (Frame<V>[]) new Frame<?>[size];
// 第三步,开始计算
// (1)开始计算:根据方法的参数,计算方法的初始Frame
Frame<V> currentFrame = computeInitialFrame(owner, method);
merge(frames, 0, currentFrame, instructionsToProcess);
// (2)开始计算:根据方法的每一条指令,计算相应的Frame
while (getCount(instructionsToProcess) > 0) {
// 获取需要处理的指令索引(insnIndex)和旧的Frame(oldFrame)
int insnIndex = getFirst(instructionsToProcess);
Frame<V> oldFrame = frames[insnIndex];
instructionsToProcess[insnIndex] = false;
// 模拟每一条指令的执行
try {
AbstractInsnNode insnNode = method.instructions.get(insnIndex);
int insnOpcode = insnNode.getOpcode();
int insnType = insnNode.getType();
// 这三者并不是真正的指令,分别表示Label、LineNumberTable和Frame
if (insnType == AbstractInsnNode.LABEL
|| insnType == AbstractInsnNode.LINE
|| insnType == AbstractInsnNode.FRAME) {
merge(frames, insnIndex + 1, oldFrame, instructionsToProcess);
}
else {
// 这里是真正的指令
currentFrame.init(oldFrame).execute(insnNode, interpreter);
if (insnNode instanceof JumpInsnNode) {
JumpInsnNode jumpInsn = (JumpInsnNode) insnNode;
// if之后的语句
if (insnOpcode != GOTO) {
merge(frames, insnIndex + 1, currentFrame, instructionsToProcess);
}
// if和goto跳转之后的位置
int jumpInsnIndex = insnList.indexOf(jumpInsn.label);
merge(frames, jumpInsnIndex, currentFrame, instructionsToProcess);
}
else if (insnNode instanceof LookupSwitchInsnNode) {
LookupSwitchInsnNode lookupSwitchInsn = (LookupSwitchInsnNode) insnNode;
// lookupswitch的default情况
int targetInsnIndex = insnList.indexOf(lookupSwitchInsn.dflt);
merge(frames, targetInsnIndex, currentFrame, instructionsToProcess);
// lookupswitch的各种case情况
for (int i = 0; i < lookupSwitchInsn.labels.size(); ++i) {
LabelNode label = lookupSwitchInsn.labels.get(i);
targetInsnIndex = insnList.indexOf(label);
merge(frames, targetInsnIndex, currentFrame, instructionsToProcess);
}
}
else if (insnNode instanceof TableSwitchInsnNode) {
TableSwitchInsnNode tableSwitchInsn = (TableSwitchInsnNode) insnNode;
// tableswitch的default情况
int targetInsnIndex = insnList.indexOf(tableSwitchInsn.dflt);
merge(frames, targetInsnIndex, currentFrame, instructionsToProcess);
// tableswitch的各种case情况
for (int i = 0; i < tableSwitchInsn.labels.size(); ++i) {
LabelNode label = tableSwitchInsn.labels.get(i);
targetInsnIndex = insnList.indexOf(label);
merge(frames, targetInsnIndex, currentFrame, instructionsToProcess);
}
}
else if (insnOpcode != ATHROW && (insnOpcode < IRETURN || insnOpcode > RETURN)) {
merge(frames, insnIndex + 1, currentFrame, instructionsToProcess);
}
}
}
catch (AnalyzerException e) {
throw new AnalyzerException(e.node, "Error at instruction " + insnIndex + ": " + e.getMessage(), e);
}
}
return frames;
}
private int getCount(boolean[] array) {
int count = 0;
for (boolean flag : array) {
if (flag) {
count++;
}
}
return count;
}
private int getFirst(boolean[] array) {
int length = array.length;
for (int i = 0; i < length; i++) {
boolean flag = array[i];
if (flag) {
return i;
}
}
return -1;
}
private Frame<V> computeInitialFrame(String owner, MethodNode method) {
Frame<V> frame = new Frame<>(method.maxLocals, method.maxStack);
int currentLocal = 0;
// 第一步,判断是否需要存储this变量
boolean isInstanceMethod = (method.access & ACC_STATIC) == 0;
if (isInstanceMethod) {
Type ownerType = Type.getObjectType(owner);
V value = interpreter.newParameterValue(isInstanceMethod, currentLocal, ownerType);
frame.setLocal(currentLocal, value);
currentLocal++;
}
// 第二步,将方法的参数存入到local variable内
Type[] argumentTypes = Type.getArgumentTypes(method.desc);
for (Type argumentType : argumentTypes) {
V value = interpreter.newParameterValue(isInstanceMethod, currentLocal, argumentType);
frame.setLocal(currentLocal, value);
currentLocal++;
if (argumentType.getSize() == 2) {
frame.setLocal(currentLocal, interpreter.newEmptyValue(currentLocal));
currentLocal++;
}
}
// 第三步,将local variable的剩余位置填补上空值
while (currentLocal < method.maxLocals) {
frame.setLocal(currentLocal, interpreter.newEmptyValue(currentLocal));
currentLocal++;
}
// 第四步,设置返回值类型
frame.setReturn(interpreter.newReturnTypeValue(Type.getReturnType(method.desc)));
return frame;
}
/**
* Merge old frame with new frame.
*
* @param frames 所有的frame信息。
* @param insnIndex 当前指令的索引。
* @param newFrame 新的frame
* @param instructionsToProcess 记录哪一条指令需要处理
* @throws AnalyzerException 分析错误,抛出此异常
*/
private void merge(Frame<V>[] frames, int insnIndex, Frame<V> newFrame, boolean[] instructionsToProcess) throws AnalyzerException {
boolean changed;
Frame<V> oldFrame = frames[insnIndex];
if (oldFrame == null) {
frames[insnIndex] = new Frame<>(newFrame);
changed = true;
}
else {
changed = oldFrame.merge(newFrame, interpreter);
}
if (changed && !instructionsToProcess[insnIndex]) {
instructionsToProcess[insnIndex] = true;
}
}
}
如何使用Analyzer类
使用Analyzer类非常简单,它的主要目的就是分析,也就是调用它的analyze方法。
虽然下面的两行代码比较简单,但是它包含了Analyzer、Frame、Interpreter和Value四个类的应用:
┌── Analyzer
│ ┌── Value ┌── Interpreter
│ │ │
Analyzer<BasicValue> analyzer = new Analyzer<>(new BasicInterpreter());
Frame<BasicValue>[] frames = analyzer.analyze(owner, mn);
│ │
│ └── Value
└── Frame
另外,如果我们想验证一下MockAnalyzer类是否可以正常工作,可以将HelloWorldFrameTree类当中的Analyzer类替换成MockAnalyzer类:
MockAnalyzer<V> analyzer = new MockAnalyzer<>(interpreter);
Frame<V>[] frames = analyzer.analyze(owner, mn);
总结
本文内容总结如下:
- 第一点,介绍
Analyzer类的主要组成部分。 - 第二点,借助于一个简化的
Analyzer类(MockAnalyzer),来理解data flow analysis的工作原理。虽然我们没有介绍control flow analysis,但是大家只要追踪一下newControlFlowEdge和newControlFlowExceptionEdge方法就知道了。 - 第三点,如何使用Analyzer类。其实,就是调用Analyzer类的
analyze方法,得到生成的Frame[]信息,然后再利用这个Frame[]信息做进一步的分析。
┌──────────┬─────────────┐
│ │ Analyzer │
│ Fixed ├─────────────┤
│ │ Frame │
├──────────┼─────────────┤
│ │ Interpreter │
│ Variable ├─────────────┤
│ │ Value │
└──────────┴─────────────┘