
ClassReader 类
ClassReader 类和 ClassWriter 类,从功能角度来说,是完全相反的两个类,一个用于读取 .class 文件,另一个用于生成 .class 文件。
class info
第一个部分,ClassReader 的父类是 Object 类。与 ClassWriter 类不同的是,ClassReader 类并没有继承自 ClassVisitor 类。
ClassReader 类的定义如下:
public class ClassReader {
}
ClassWriter 类的定义如下:
public class ClassWriter extends ClassVisitor {
}
fields
第二个部分,ClassReader 类定义的字段有哪些。我们选取出其中的 3 个字段进行介绍,即 classFileBuffer 字段、cpInfoOffsets 字段和 header 字段。
public class ClassReader {
// 第 1 组,真实的数据部分
final byte[] classFileBuffer;
// 第 2 组,数据的索引信息
private final int[] cpInfoOffsets;
public final int header;
}
为什么选择这 3 个字段呢?因为这 3 个字段能够体现出 ClassReader 类处理 .class 文件的整体思路:
- 第 1 组,
classFileBuffer字段:它里面包含的信息,就是从.class文件中读取出来的字节码数据。 - 第 2 组,
cpInfoOffsets字段和header字段:它们分别标识了classFileBuffer中数据里包含的常量池(constant pool)和访问标识(access flag)的位置信息。
我们拿到 classFileBuffer 字段后,一个主要目的就是对它的内容进行修改,来实现一个新的功能。它处理的大体思路是这样的:
.class 文件 --> ClassReader --> byte[] --> 经过各种转换 --> ClassWriter --> byte[] --> .class 文件
- 第一,从一个
.class文件(例如HelloWorld.class)开始,它可能存储于磁盘的某个位置; - 第二,使用
ClassReader类将这个.class文件的内容读取出来,其实这些内容(byte[])就是ClassReader对象中的classFileBuffer字段的内容; - 第三,为了增加某些功能,就对这些原始内容(
byte[])进行转换; - 第四,等各种转换都完成之后,再交给
ClassWriter类处理,调用它的toByteArray()方法,从而得到新的内容(byte[]); - 第五,将新生成的内容(
byte[])存储到一个具体的.class文件中,那么这个新的.class文件就具备了一些新的功能。
constructors
第三个部分,ClassReader 类定义的构造方法有哪些。在 ClassReader 类当中定义了 5 个构造方法。但是,从本质上来说,这 5 个构造方法本质上是同一个构造方法的不同表现形式。其中,最常用的构造方法有两个:
- 第一个是
ClassReader cr = new ClassReader("sample.HelloWorld"); - 第二个是
ClassReader cr = new ClassReader(bytes);
public class ClassReader {
public ClassReader(final String className) throws IOException { // 第一个构造方法(常用)
this(
readStream(ClassLoader.getSystemResourceAsStream(className.replace('.', '/') + ".class"), true)
);
}
public ClassReader(final byte[] classFile) { // 第二个构造方法(常用)
this(classFile, 0, classFile.length);
}
public ClassReader(final byte[] classFileBuffer, final int classFileOffset, final int classFileLength) {
this(classFileBuffer, classFileOffset, true);
}
ClassReader( // 这是最根本、最本质的构造方法
final byte[] classFileBuffer,
final int classFileOffset,
final boolean checkClassVersion) {
// ......
}
private static byte[] readStream(final InputStream inputStream, final boolean close) throws IOException {
if (inputStream == null) {
throw new IOException("Class not found");
}
try (ByteArrayOutputStream outputStream = new ByteArrayOutputStream()) {
byte[] data = new byte[INPUT_STREAM_DATA_CHUNK_SIZE];
int bytesRead;
while ((bytesRead = inputStream.read(data, 0, data.length)) != -1) {
outputStream.write(data, 0, bytesRead);
}
outputStream.flush();
return outputStream.toByteArray();
} finally {
if (close) {
inputStream.close();
}
}
}
}
所有构造方法,本质上都执行下面的逻辑:
public class ClassReader {
ClassReader(final byte[] classFileBuffer, final int classFileOffset, final boolean checkClassVersion) {
this.classFileBuffer = classFileBuffer;
// Check the class' major_version.
// This field is after the magic and minor_version fields, which use 4 and 2 bytes respectively.
if (checkClassVersion && readShort(classFileOffset + 6) > Opcodes.V16) {
throw new IllegalArgumentException("Unsupported class file major version " + readShort(classFileOffset + 6));
}
// Create the constant pool arrays.
// The constant_pool_count field is after the magic, minor_version and major_version fields,
// which use 4, 2 and 2 bytes respectively.
int constantPoolCount = readUnsignedShort(classFileOffset + 8);
cpInfoOffsets = new int[constantPoolCount];
// Compute the offset of each constant pool entry,
// as well as a conservative estimate of the maximum length of the constant pool strings.
// The first constant pool entry is after the magic, minor_version, major_version and constant_pool_count fields,
// which use 4, 2, 2 and 2 bytes respectively.
int currentCpInfoIndex = 1;
int currentCpInfoOffset = classFileOffset + 10;
// The offset of the other entries depend on the total size of all the previous entries.
while (currentCpInfoIndex < constantPoolCount) {
cpInfoOffsets[currentCpInfoIndex++] = currentCpInfoOffset + 1;
int cpInfoSize;
switch (classFileBuffer[currentCpInfoOffset]) {
case Symbol.CONSTANT_FIELDREF_TAG:
case Symbol.CONSTANT_METHODREF_TAG:
case Symbol.CONSTANT_INTERFACE_METHODREF_TAG:
case Symbol.CONSTANT_INTEGER_TAG:
case Symbol.CONSTANT_FLOAT_TAG:
case Symbol.CONSTANT_NAME_AND_TYPE_TAG:
cpInfoSize = 5;
break;
case Symbol.CONSTANT_DYNAMIC_TAG:
cpInfoSize = 5;
break;
case Symbol.CONSTANT_INVOKE_DYNAMIC_TAG:
cpInfoSize = 5;
break;
case Symbol.CONSTANT_LONG_TAG:
case Symbol.CONSTANT_DOUBLE_TAG:
cpInfoSize = 9;
currentCpInfoIndex++;
break;
case Symbol.CONSTANT_UTF8_TAG:
cpInfoSize = 3 + readUnsignedShort(currentCpInfoOffset + 1);
break;
case Symbol.CONSTANT_METHOD_HANDLE_TAG:
cpInfoSize = 4;
break;
case Symbol.CONSTANT_CLASS_TAG:
case Symbol.CONSTANT_STRING_TAG:
case Symbol.CONSTANT_METHOD_TYPE_TAG:
case Symbol.CONSTANT_PACKAGE_TAG:
case Symbol.CONSTANT_MODULE_TAG:
cpInfoSize = 3;
break;
default:
throw new IllegalArgumentException();
}
currentCpInfoOffset += cpInfoSize;
}
// The Classfile's access_flags field is just after the last constant pool entry.
header = currentCpInfoOffset;
}
}
上面的代码,要结合 ClassFile 的结构进行理解:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
methods
第四个部分,ClassReader 类定义的方法有哪些。
getXxx() 方法
这里介绍的几个 getXxx() 方法,都是在 header 字段的基础上获得的:
public class ClassReader {
public int getAccess() {
return readUnsignedShort(header);
}
public String getClassName() {
// this_class is just after the access_flags field (using 2 bytes).
return readClass(header + 2, new char[maxStringLength]);
}
public String getSuperName() {
// super_class is after the access_flags and this_class fields (2 bytes each).
return readClass(header + 4, new char[maxStringLength]);
}
public String[] getInterfaces() {
// interfaces_count is after the access_flags, this_class and super_class fields (2 bytes each).
int currentOffset = header + 6;
int interfacesCount = readUnsignedShort(currentOffset);
String[] interfaces = new String[interfacesCount];
if (interfacesCount > 0) {
char[] charBuffer = new char[maxStringLength];
for (int i = 0; i < interfacesCount; ++i) {
currentOffset += 2;
interfaces[i] = readClass(currentOffset, charBuffer);
}
}
return interfaces;
}
}
同样,上面的几个 getXxx() 方法也需要参考 ClassFile 结构来理解:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
假如,有如下一个类:
import java.io.Serializable;
public class HelloWorld extends Exception implements Serializable, Cloneable {
}
我们可以使用 ClassReader 类中的 getXxx() 方法来获取相应的信息:
import lsieun.utils.FileUtils;
import org.objectweb.asm.ClassReader;
import java.util.Arrays;
public class HelloWorldRun {
public static void main(String[] args) throws Exception {
String relative_path = "sample/HelloWorld.class";
String filepath = FileUtils.getFilePath(relative_path);
byte[] bytes = FileUtils.readBytes(filepath);
//(1)构建 ClassReader
ClassReader cr = new ClassReader(bytes);
// (2) 调用 getXxx() 方法
int access = cr.getAccess();
System.out.println("access: " + access);
String className = cr.getClassName();
System.out.println("className: " + className);
String superName = cr.getSuperName();
System.out.println("superName: " + superName);
String[] interfaces = cr.getInterfaces();
System.out.println("interfaces: " + Arrays.toString(interfaces));
}
}
输出结果:
access: 33
className: sample/HelloWorld
superName: java/lang/Exception
interfaces: [java/io/Serializable, java/lang/Cloneable]
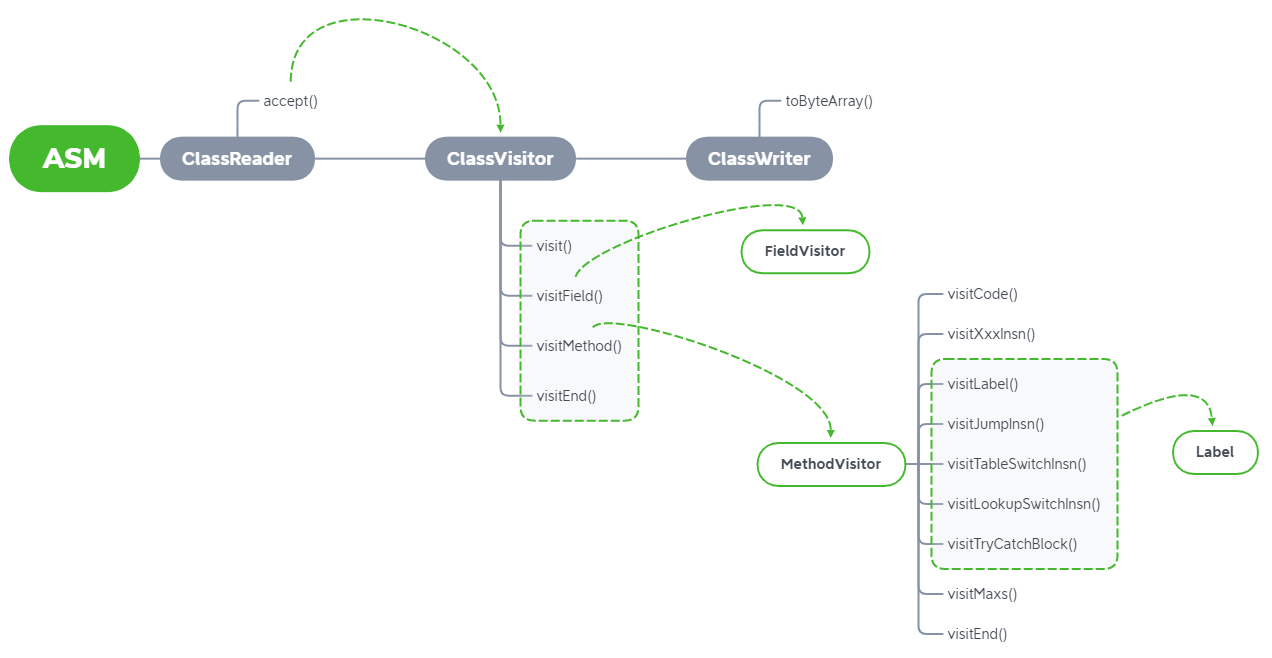
accept() 方法
在 ClassReader 类当中,有一个 accept() 方法,这个方法接收一个 ClassVisitor 类型的参数,因此 accept() 方法是将 ClassReader 和 ClassVisitor 进行连接的“桥梁”。accept() 方法的代码逻辑就是按照一定的顺序来调用 ClassVisitor 当中的 visitXxx() 方法。
public class ClassReader {
// A flag to skip the Code attributes.
public static final int SKIP_CODE = 1;
// A flag to skip the SourceFile, SourceDebugExtension,
// LocalVariableTable, LocalVariableTypeTable,
// LineNumberTable and MethodParameters attributes.
public static final int SKIP_DEBUG = 2;
// A flag to skip the StackMap and StackMapTable attributes.
public static final int SKIP_FRAMES = 4;
// A flag to expand the stack map frames.
public static final int EXPAND_FRAMES = 8;
public void accept(final ClassVisitor classVisitor, final int parsingOptions) {
accept(classVisitor, new Attribute[0], parsingOptions);
}
public void accept(
final ClassVisitor classVisitor,
final Attribute[] attributePrototypes,
final int parsingOptions) {
Context context = new Context();
context.attributePrototypes = attributePrototypes;
context.parsingOptions = parsingOptions;
context.charBuffer = new char[maxStringLength];
// Read the access_flags, this_class, super_class, interface_count and interfaces fields.
char[] charBuffer = context.charBuffer;
int currentOffset = header;
int accessFlags = readUnsignedShort(currentOffset);
String thisClass = readClass(currentOffset + 2, charBuffer);
String superClass = readClass(currentOffset + 4, charBuffer);
String[] interfaces = new String[readUnsignedShort(currentOffset + 6)];
currentOffset += 8;
for (int i = 0; i < interfaces.length; ++i) {
interfaces[i] = readClass(currentOffset, charBuffer);
currentOffset += 2;
}
// ......
// Visit the class declaration. The minor_version and major_version fields start 6 bytes before
// the first constant pool entry, which itself starts at cpInfoOffsets[1] - 1 (by definition).
classVisitor.visit(readInt(cpInfoOffsets[1] - 7), accessFlags, thisClass, signature, superClass, interfaces);
// ......
// Visit the fields and methods.
int fieldsCount = readUnsignedShort(currentOffset);
currentOffset += 2;
while (fieldsCount-- > 0) {
currentOffset = readField(classVisitor, context, currentOffset);
}
int methodsCount = readUnsignedShort(currentOffset);
currentOffset += 2;
while (methodsCount-- > 0) {
currentOffset = readMethod(classVisitor, context, currentOffset);
}
// Visit the end of the class.
classVisitor.visitEnd();
}
}
另外,我们也可以回顾一下 ClassVisitor 类中 visitXxx() 方法的调用顺序:
visit
[visitSource][visitModule][visitNestHost][visitPermittedSubclass][visitOuterClass]
(
visitAnnotation |
visitTypeAnnotation |
visitAttribute
)*
(
visitNestMember |
visitInnerClass |
visitRecordComponent |
visitField |
visitMethod
)*
visitEnd
如何使用 ClassReader 类
The ASM core API for generating and transforming compiled Java classes is based on the ClassVisitor abstract class.
在现阶段,我们接触了 ClassVisitor、ClassWriter 和 ClassReader 类,因此可以介绍 Class Transformation 的操作。
import lsieun.utils.FileUtils;
import org.objectweb.asm.ClassReader;
import org.objectweb.asm.ClassVisitor;
import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.Opcodes;
public class HelloWorldTransformCore {
public static void main(String[] args) {
String relative_path = "sample/HelloWorld.class";
String filepath = FileUtils.getFilePath(relative_path);
byte[] bytes1 = FileUtils.readBytes(filepath);
//(1)构建 ClassReader
ClassReader cr = new ClassReader(bytes1);
//(2)构建 ClassWriter
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
//(3)串连 ClassVisitor
int api = Opcodes.ASM9;
ClassVisitor cv = new ClassVisitor(api, cw) { /**/ };
//(4)结合 ClassReader 和 ClassVisitor
int parsingOptions = ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES;
cr.accept(cv, parsingOptions);
//(5)生成 byte[]
byte[] bytes2 = cw.toByteArray();
FileUtils.writeBytes(filepath, bytes2);
}
}
代码的整体处理流程是如下这样的:
.class --> ClassReader --> ClassVisitor1 ... --> ClassVisitorN --> ClassWriter --> .class 文件
我们可以将整体的处理流程想像成一条河流,那么
- 第一步,构建
ClassReader。生成的ClassReader对象,它是这条“河流”的“源头”。 - 第二步,构建
ClassWriter。生成的ClassWriter对象,它是这条“河流”的“归处”,它可以想像成是“百川东到海”中的“大海”。 - 第三步,串连
ClassVisitor。生成的ClassVisitor对象,它是这条“河流”上的重要节点,可以想像成一个“水库”;可以有多个ClassVisitor对象,也就是在这条“河流”上存在多个“水库”,这些“水库”可以对“河水”进行一些处理,最终会这些“水库”的水会流向“大海”;也就是说多个ClassVisitor对象最终会连接到ClassWriter对象上。 - 第四步,结合
ClassReader和ClassVisitor。在ClassReader类上,有一个accept()方法,它接收一个ClassVisitor类型的对象;换句话说,就是将“河流”的“源头”和后续的“水库”连接起来。 - 第五步,生成
byte[]。到这一步,就是所有的“河水”都流入ClassWriter这个“大海”当中,这个时候我们调用ClassWriter.toByteArray()方法,就能够得到byte[]内容。
parsingOptions 参数
在 ClassReader 类当中,accept() 方法接收一个 int 类型的 parsingOptions 参数。
public void accept(final ClassVisitor classVisitor, final int parsingOptions)
parsingOptions 参数可以选取的值有以下 5 个:
0ClassReader.SKIP_CODEClassReader.SKIP_DEBUGClassReader.SKIP_FRAMESClassReader.EXPAND_FRAMES
┌─── SKIP_CODE
│
├─── SKIP_DEBUG
ClassReader::parsingOptions ───┤
├─── SKIP_FRAMES
│
└─── EXPAND_FRAMES
┌─── SKIP_CODE ───────┼─── method_info ───┼─── Code
│
│ ┌─── SourceFile
│ ┌─── classfile ─────┤
│ │ └─── SourceDebugExtension
├─── SKIP_DEBUG ──────┤
│ │ ┌─── MethodParameters
│ │ │
ClassReader::parsingOptions ───┤ └─── method_info ───┤ ┌─── LocalVariableTable
│ │ │
│ └─── code ───────────────┼─── LocalVariableTypeTable
│ │
│ └─── LineNumberTable
│
├─── SKIP_FRAMES ─────┼─── method_info ───┼─── code ───┼─── StackMapTable
│
└─── EXPAND_FRAMES ───┼─── method_info ───┼─── code ───┼─── StackMapTable
推荐使用:
- 在调用
ClassReader.accept()方法时,其中的parsingOptions参数,推荐使用ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES。 - 在创建
ClassWriter对象时,其中的flags参数,推荐使用ClassWriter.COMPUTE_FRAMES。
示例代码如下:
ClassReader cr = new ClassReader(bytes);
int parsingOptions = ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES;
cr.accept(cv, parsingOptions);
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES);
为什么我们推荐使用 ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES 呢?因为使用这样的一个值,可以生成最少的 ASM 代码,但是又能实现完整的功能。
0:会生成所有的 ASM 代码,包括调试信息、frame 信息和代码信息。ClassReader.SKIP_CODE:会忽略代码信息,例如,会忽略对于MethodVisitor.visitXxxInsn()方法的调用。ClassReader.SKIP_DEBUG:会忽略调试信息,例如,会忽略对于MethodVisitor.visitParameter()、MethodVisitor.visitLineNumber()和MethodVisitor.visitLocalVariable()等方法的调用。ClassReader.SKIP_FRAMES:会忽略 frame 信息,例如,会忽略对于MethodVisitor.visitFrame()方法的调用。ClassReader.EXPAND_FRAMES:会对 frame 信息进行扩展,例如,会对MethodVisitor.visitFrame()方法的参数有影响。
简而言之,使用 ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES 的目的是功能完整、代码少、复杂度低,:
- 不使用
ClassReader.SKIP_CODE,使代码的功能保持完整。 - 使用
ClassReader.SKIP_DEBUG,减少不必要的调试信息,会使代码量减少。 - 使用
ClassReader.SKIP_FRAMES,降低代码的复杂度。 - 不使用
ClassReader.EXPAND_FRAMES,降低代码的复杂度。
对于这些参数的使用,我们可以在 PrintASMCodeCore 类的基础上进行实验。
我们使用 ClassReader.SKIP_DEBUG 的时候,就不会生成调试信息。因为这些调试信息主要是记录某一条 instruction 在代码当中的行数,以及变量的名字等信息;如果没有这些调试信息,也不会影响程序的正常运行,也就是说功能不受影响,因此省略这些信息,就会让 ASM 代码尽可能的简洁。
我们使用 ClassReader.SKIP_FRAMES 的时候,就会忽略 frame 的信息。为什么要忽略这些 frame 信息呢?因为 frame 计算的细节会很繁琐,需要处理的情况也有很多,总的来说,就是比较麻烦。我们解决这个麻烦的方式,就是让 ASM 帮助我们来计算 frame 的情况,也就是在创建 ClassWriter 对象的时候使用 ClassWriter.COMPUTE_FRAMES 选项。
在刚开始学习 ASM 的时候,对于 parsingOptions 参数,我们推荐使用 ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES 的组合值。但是,以后,随着大家对 ASM 的知识越来越熟悉,或者随着功能需求的变化,大家可以尝试着使用其它的选项值。
总结
本文主要对 ClassReader 类进行了介绍,内容总结如下:
- 第一点,了解
ClassReader类的成员都有哪些。 - 第二点,如何使用
ClassReader类,来进行 Class Transformation 的操作。 - 第三点,在
ClassReader类当中,对于accept()方法的parsingOptions参数,我们推荐使用ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES。